Semantic textual similarity in clinical domain texts
Overview
Semantic Textual Similarity (STS) captures the degree of semantic similarity between texts. It plays an important role in many natural language processing applications such as text summarization, question answering, machine translation, information retrieval, dialog systems, plagiarism detection, and query ranking.
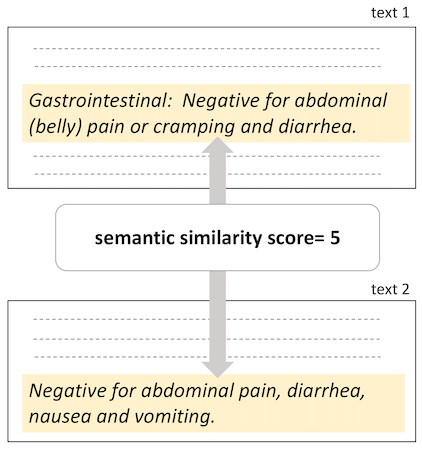
In this project, we calculate semantic similarity between clinical domain sentence pairs, and assign them semantic similarity scores from 0 (low semantic similarity) to 5 (high semantic similarity).
Approach
Dataset
The datasets consist of sentence pairs annotated with a semantic similarity from 0 (low semantic similarity) to 5 (high semantic similarity). This task uses three datasets; one English dataset, and two Japanese datasets. One of the Japanese datasets is publicly available and can be freely downloaded from here. This dataset was created from sentences extracted from case reports publications extracted from the CiNii database. The rest of the datasets (English and Japanese) cannot be shared publicly because they were created from Electronic Medical Records (EMR).
Models
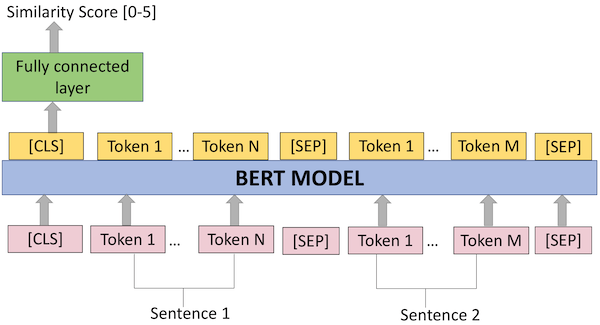
The task can be treated as a regression model (continuous scores between 0 and 5) or sequence classification task with 6 classes (discrete scores [0,1,2,3,4,5]).We used Clinical BERT model for the English dataset. For the Japanese models we used Japanese BERT and Clinical Japanese BERT models. The codes for the BERT regression and sequence classification models can be found in this Github repository.
Paper
For detailed information on the corpus and models read our papers below.